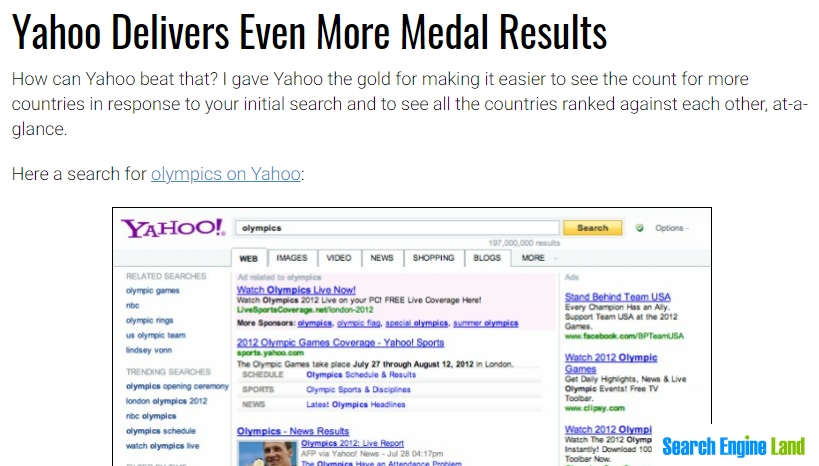
Explored ways to feature relevant, engaging Tumblr content in Yahoo web search results.
Ask
After Yahoo acquired Tumblr, Search leadership asked me to find a way to feature Tumblr content in web search results.
Process
I started out with several things to consider:
- Understanding the type of content on Tumblr
- Determining what content, if any, could map to real web search user needs
- Figuring out what metadata we could extract from Tumblr posts and whether it was enough to work well in our content management platform
- Learning as much as we could from what little data the Tumblr team could share with us
Because I was unable to discover much evidence of existing Yahoo search-to-Tumblr content behavior in our logs, and the nature of Tumblr’s content is freewheeling and relatively unstructured, we had to experiment.
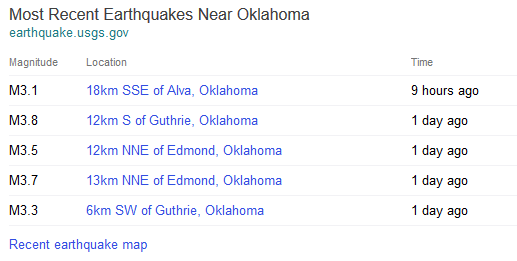
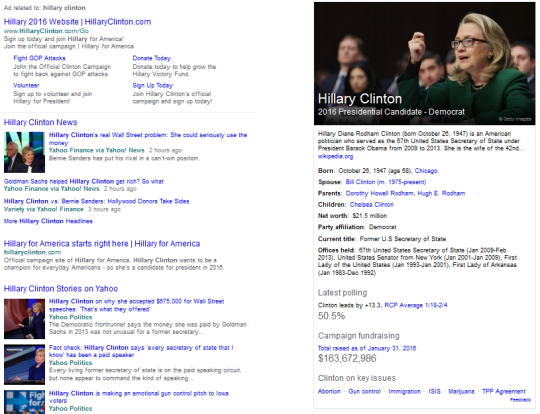
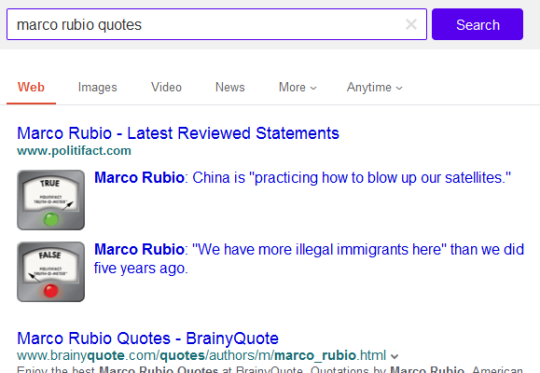
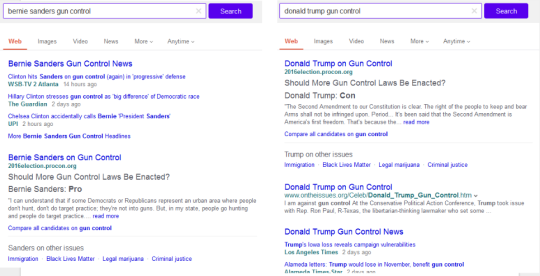
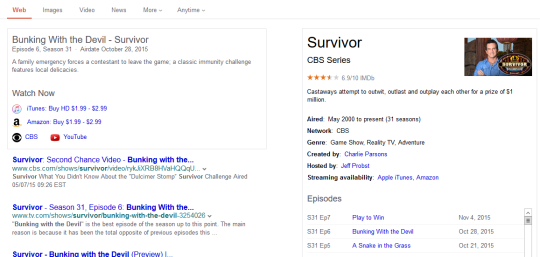
The first test featured content from specific Tumblr users (celebrities, online personalities, organizations–entities with discrete matching queries) in a simple image carousel. Limitations of this approach: only image-type posts could be displayed, so blogs with text posts, links, etc. would appear with limited results or none at all, despite frequent updating; we could only trigger on keywords that had a clear match to a single blog (e.g., Beyonce, ZooBorns). As a result, coverage was low, and leadership tasked us with significantly expanding the experience.
“[Emily] took on a very demanding team that wanted to create a new experience for users with Tumblr content. She patiently worked with the team and in many instances stepped in to help move the project forward. Without her it would have taken much longer to launch the experience on Search.”
Product Manager, Search
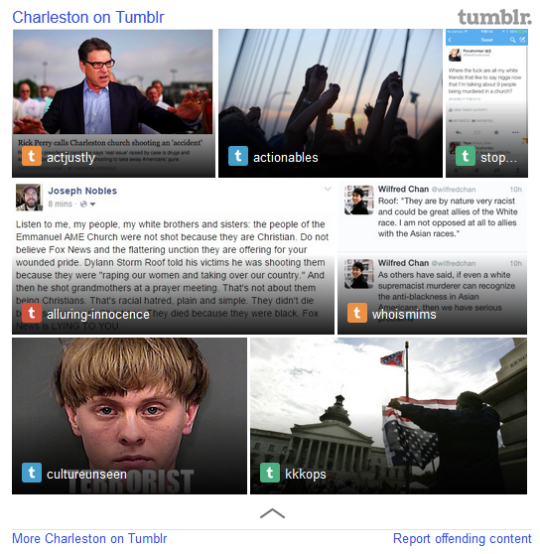
To accomplish this, I needed to rely on automatic triggering methods that offered far less control over what content appeared in search results. Despite concerns about relevance and quality, we launched a test for a small percentage of search traffic. The initial test had to be taken offline within days because, although the backend team took steps to remove content flagged as “adult,” pornographic results (and worse) slipped through.
Search leadership was determined, however, and resources were provided to dramatically improve the indexing for quality and cleanliness. The backend team also added logic for when to return content at all, based on timeliness and other factors. A visual designer was brought in to collaborate a unique template for Tumblr that accounted for the variable types of content and included more Tumblr branding (color, logos). The UX and content improvements launched as a test for a small percentage of search traffic, and although metrics weren’t impressive, it didn’t cause major problems, and the feature launched for all desktop web traffic.
“Emily did an outstanding job on the Tumblr [search experience] presentation for the Tumblr team. She has built a [search experience] that puts a stake in the ground until Science can develop more precise triggering.”
Product Marketing Manager, Search
Seeking to experiment further in hopes of improving and better understanding its performance, I took the initiative to categorize queries that triggered the Tumblr module and identify categories that might be well-served with Tumblr content. I used existing keyword lists roughly mapping to a dozen or so categories and set up a test bucket version of the module with only these categories with logging for each. I also wanted to see if other factors affected performance, including where the module appeared on the page (“slotting”) and how consistently it appeared (whether to ignore backend display logic). I tracked and compared my experiment’s performance to the primary module’s on a weekly basis, using that data to make small tweaks to each category along the way.
Result
The great Tumblr in search experiment ended after about a year and a half, when leadership decided the investment was no longer justifiable. Despite the effort’s ultimate failure, I was recognized for my contribution and creativity.
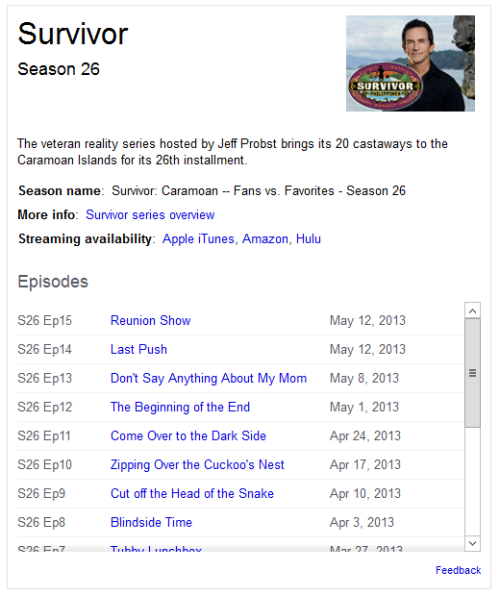
Key categories in my final experiment did show some lift in performance: food, books, holidays, fictional characters, TV series, and movie series.